A better way to read (at 350 words per minute)
I know kung fu
You know that sequence in The Matrix where Neo plugs a cable straight into his brain for the purpose of learning some mad skillz… And it only takes a few seconds. Whoah! I love that, but I wouldn’t trade my world of illusion for the speed of learning kung fu that way (because of the killer robots, among other reasons).
In so-called “real life,” we have to learn things “the hard way,” which takes a “little longer…” but what if I said it was possible to read papers much faster than you’re used to? As in, 3 or 4 times faster? As in, 350 words per minute? Sounds pretty far-fetched, but here’s where I offer you the blue pill. Eat it. Eat it!
the voice in your head that reads books to you
I’ve been interested in the idea of speed reading for some time now, and there have been a variety of interesting solutions over the years. The take-home message from speed reading books (at least the ones I’ve read) is that you need to pace yourself, and that you waste time “vocalizing” the words silently inside your head. Such books claim that if you can learn how to recognize words without speaking them to yourself, then you’ll be faster.
Well, maybe so! I haven’t been able to figure out that trick, but it sounds about right. What if I told you to perform some mental arithmetic while you read a passage in a book? As in: count backwards from 103, subtracting by 7 each time. Now see if you read faster or slower than normal… This sort of cognitive load argument suggests to me that you would, in fact, read slower if you were pronouncing the words versus not.
Or, consider the situation where you are reading a book and you “space out,” causing you to read a whole paragraph without actually remembering anything you just read. What this suggests to me is that the process of your inner voice reciting the words can become so automatic that you are able to do it without investing any attention in the process. On that basis, I do think I could train myself to read without pronouncing the words - it just needs to become automatic.
blink and you’ll miss it
Another interesting approach is rapid serial visual presentation (RSVP), in which a computer presents individual words on the screen, several hundred per-minute. I’ve tried this, and it’s a great solution for keeping the pace, but it has drawbacks.
The biggest point to detract from RSVP is the significant investment it takes to convert a document to an RSVP-formatable representation. What do you do with images? equations? tables? These don’t map onto RSVP in any easy manner, making this a non-starter for academic reading.
co-reading: the better approach
co-read (verb): to visually scan a document while that document’s words are raidly spoken to you using text-to-speech (TTS) software.
For all I know, my wife actually invented this technique some time around 2005. I’ve never heard about it elsewhere, either before or since. In its simplest version, you take advantage of your operating system’s speech facilities, which are used by the visually impaired for screen-reading. If you don’t have trouble seeing your computer display, then maybe this never occurred to you, but the general idea is that even blind people can use computers… they just use software to speak all of the text to them.
I can’t really say much about the Microsoft speech facilities, but as far as TTS is concerned, OS X has taken huge strides in the last half-decade. The new voices that shipped with OS X Lion are just fantastic, and you can get started co-reading almost immediately. Like, within 60 seconds.
First, set up a hotkey to begin speaking any words you’ve selected. Open System Preferences and click on Speech:
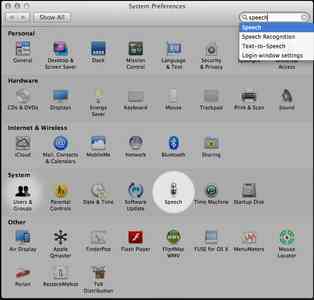
Then, click “Speak selected text when the key is pressed”. Make this into a key combination you like; I’ve chosen Option+Control+S
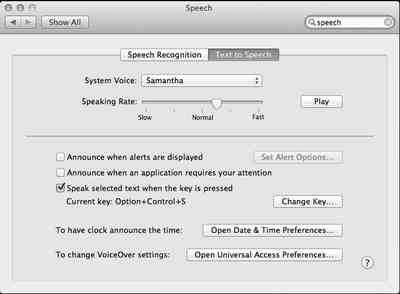
Then, open a PDF, select a page at a time, and press the key combo you just chose in order to listen to the words while you follow with your eyes. Once you’re comfortable with that, go back to the Speech preferences and crank up the Speaking Rate of the text-to-speech engine. This is the horizontal slider in the Speech preferences pane that goes from slow to Normal to Fast. Suddenly you’re co-reading faster than you thought possible.
taking it to the next level
For starters, it can be cumbersome to select the words on each page as you read through a document, so we’ll just render the whole document to mp3 - all at once. This is advantageous in several ways:
- an mp3 can be paused and resumed at will
- by looking at the length of the mp3, you can see exactly how long it will take to read the document
Don’t underestimate this second point. The ability to plan out reading, in pre-determined chunks of time, is a huge advantage.
Next, we’ll automate this process, and add on some optimizations that skip over the parts of the documents that interrupt the flow of the text (like page headers and citations).
extracting all of the text from a PDF
The general process for rendering a PDF to an audio file begins when we extract all of the words from the .PDF, and save them as a .TXT file. This is easily accomplished with pdftotext, which can be downloaded from this link, or compiled using homebrew. (highly recommended!) The official Xpdf site is here, which includes Windows binaries.
So let’s say you have a .PDF called Important Paper.pdf that you want to co-read. For the sake of this example, Important Paper.pdf is on your Desktop. First, open the terminal (in Applications/Utilities), change directories to your Desktop, and extract the text. To accomplish all that, just type the following commands into the terminal command prompt:
cd ~/Desktop
pdftotext "Important Paper.pdf"
Anyway, this creates a text file called Important Paper.txt. The quotation marks are important, because this filename has a space in it. Otherwise, the computer thinks you’re dealing with two files (one called Important and the other called Paper.pdf), because that’s what spaces mean on the command line.
Also, this last iconv step might be important, just in case the character encoding on the text file ends up being a little funky. First, try skipping this step, but if the audio steps give you an error, then come back and try this:
iconv -f ISO-8859-1 -t utf8 "Important Paper.txt" > tmpfile
mv tmpfile "Important Paper.txt"
rendering an entire TXT document to audio
Next, use the OS X speech engine to convert the .txt file into a sound file:
say -v Samantha -r 220 --data-format=alac -o "Important Paper.m4a" -f "Important Paper.txt"
I like to use the Samantha voice, which is one of the new voices that ships with OS X Lion. Alex is another good choice. The important part here is the number 220, which is the number of words per minute to speak. 100 is slow, 200 is medium, 300 is fast, and 400 is right on the brink of what I (personally) can meaningfully interpret.
Finally, convert this file to an .mp3, which is likely to be smaller and might be more portable.
ffmpeg -i "Important Paper.m4a" "Important Paper.mp3"
Of course, you can skip this step if you want; iTunes imports m4a files without complaining. You can compile ffmpeg using homebrew, or look at a point-and-click alternative like Audacity.
Now, the time has come to do this thing. Load the .PDF in one window, load the .MP3 in another window, press play on the .MP3, and learn kung fu!
removing citations
What!? Remove citations!? Yes. Well, sortof. See, citations are filled with punctuation, including commas, semicolons, and parenthesis. Usually, text-to-speech software treats these as pauses, and it can really break up the flow. Also, citations frequently appear in the middle of a sentence, and it’s just not conducive to grokking a sentence when it is interrupted. That’s why I wrote this regular expression (regexp), which removes anything inside parenthesis containing letters and something that looks like a year:
\([^\)]+?\d{4}?[^\)]*?\)
At the moment, I choose to do this as a manual step, because each document is a little different. I recommend loading the .TXT file in a text editor that supports regexp find-and-replace (emacs, TextMate, Sublime Text, others), and just replace everything with nothingness. If you’re bold and reckless, then go ahead… do it without looking:
perl -pe 's/\([^\)]+?\d{4}?[^\)]*?\)//g' "Important Paper.txt" > tmpfile
mv tmpfile "Important Paper.txt"
After you’ve done this, then go back and render the .TXT file to an mp3. Now, you can look at the citations (you’ll recognize familiar author names visually), but you won’t get tripped up when sentences are split in half by references.
Here is another good one: removing hyphenation.
perl -pe 's/-[\s\n]+//g' "Important Paper.txt" > tmpfile
mv tmpfile "Important Paper.txt"
In fact, you can edit this text file to your heart’s content. Don’t want the bibliography? Just delete it, because you’re not going to want to listen to it. Get rid of page numbers, page headings and footers, and anything else that isn’t the actual content of the paper. If you don’t want to hear it, delete it.
automating the whole process
Save the following as co-read.sh, or download it from github.
#!/bin/bash
WPM=300
INFILE=$1
BASENAME=`basename -s .pdf $INFILE`
TXTFILE=/tmp/tmp.txt
SNDFILE=/tmp/tmp.m4a
MP3FILE=$BASENAME.mp3
TMPFILE=/tmp/tmpfile
echo "extracting text from $INFILE"
pdftotext "$INFILE" "$TXTFILE"
iconv -f ISO-8859-1 -t utf8 "$TXTFILE" > $TMPFILE
say -v Samantha -r $WPM --data-format=alac -o "$SNDFILE" -f $TMPFILE
ffmpeg -i "$SNDFILE" "$MP3FILE"
echo "wrote to $MP3FILE"
Then, make it executable and test it out with your Important Paper:
./co-read.sh "Important Paper.pdf"
That’s it. This chugs along, producing an audio file (the mp3) that goes at 300 words per minute. If you want it to go slower, then change $WPM to 250 or something. You have the mp3 now, so get cracking!
how fast is it?
How fast does this whole process go? Fast! I can responsibly get through 25 dense pages in about 80 minutes. The rendering process takes less than 10 minutes. Like I said, since you can look at the length of the MP3 to determine how long the document will take, I can also budget my time better… and that contributes to further time savings because I only do this when I’m in the right state of mind. (which is to say: after chugging a pot of green tea)
a caveat, and an appeal
This process is written for OS X, but it will wwork almost as well on Linux using Festival/Festivox TTS. If someone would adapt the process to Windows and post a comment about it, I’m sure others will appreciate that.
(an aside: when the PDF doesn’t “highlight”)
There’s something you need to understand about PDFs. Much of the time, they are basically just pictures, which have been scanned from sheets of paper, and which are stored in the PDF as a collection of pictures. This makes as much sense to TTS software as reading a picture of a sunset or a kitten (which is to say it doesn’t make any sense at all).
In order to make this PDF “readable”, it must be passed through an Optical Character Recognition (OCR) processor. If you purchased a scanner, you might have some OCR software lurking on your computer. Adobe Acrobat X Pro does a pretty good job - I’d go so far as to recommend it.
OCR software will look at pictures, then try to notice anything in the picture that looks like a letter. If it finds letters, then it annotates the PDF by putting an invisible, selectable letter on top of the picture of that letter. Later on, you can use your mouse to highlight these invisible letters, but it will look just about right because the pictures of the real letters are right underneath.
When you paste the clipboard, it’s probably going to contain the text you just highlighted… This specific detail comes down to the quality of the OCR software used, as well as the quality of the scanned image.